
La déduplication des données sert à optimiser l’espace disque. Il s’agit d’une technique de stockage de données qui consiste à factoriser les séquences de données identiques d’un volume afin d’économiser l’espace disque utilisé. L’objectif est de stocker davantage de données dans moins d’espace. Dans cet article nous allons mettre en place la déduplication des données sur Windows Serveur 2012. *
*
Comment fonctionne la déduplication des données ?
La fonction de déduplication segmente un flux de données entrant par exemple un fichier. Un identifiant unique est attribué à chaque segment de données et est comparé aux segments de données précédemment stockés. Si le segment n’existe pas encore sur le disque, il est stocké sinon il n’est pas de nouveau stocké mais une référence vers celui-ci est créée. Dans cet exemple chaque carré représente un segment, à gauche sans déduplication et à droite avec, on gagne donc de l’espace.
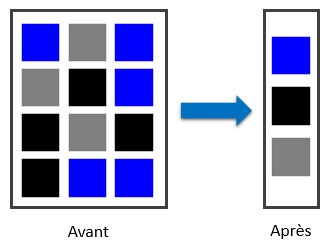
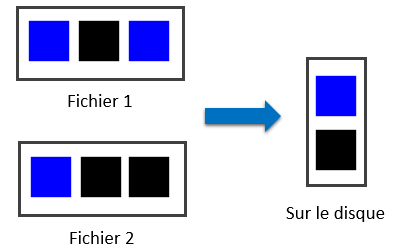
Exemple avec deux fichiers, les blocs identiques ne sont stockés qu’une seule fois:
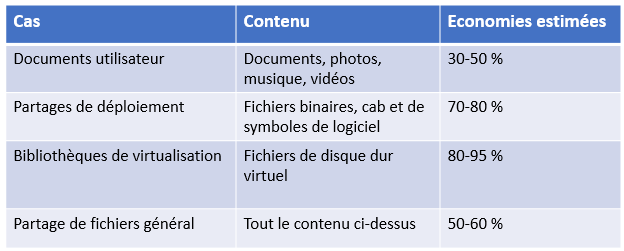
Avantages
La déduplication des données permet de réduire sensiblement les besoins de stockage tout en améliorant l’efficacité de la bande passante. Le processus de déduplication des données permet alors de réduire les coûts de stockage en limitant le nombre de disques nécessaires. L’espace gagné grâce cette fonctionnalité dépend du type de fichier:
Implémentation sur Windows serveur 2012
Installation
Sachez que la déduplication des données a été introduite sur Windows Server à partir de la version 2012, il vous sera impossible de l’utiliser dans des versions ultérieures à celle-ci. En revanche elle est disponible sur Windows Server 2016 dans une version encore plus performante que 2012.
Nous allons commencer par installer le rôle sur notre serveur. Dans le gestionnaire de serveur, cliquez sur « Gérer » puis « Ajouter des rôles et fonctionnalités ».
** *
Laissez « Installation basée sur un rôle ou une fonctionnalité » coché et cliquez sur « Suivant«

*
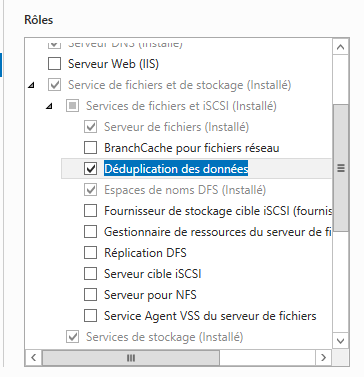
Sur la fenêtre suivante, sélectionnez votre serveur et cliquez à nouveau sur «Suivant ». Pour permettre d’effectuer la déduplication nous allons devoir installer le rôle adéquat. Pour cela dépliez la partie « Service de fichiers et de stockage » puis dépliez « Services de fichiers et iSCSI » et sélectionnez « Déduplication des données ». Cliquez sur « Suivant ». N’installez pas de fonctionnalité supplémentaire nous auront uniquement besoin du rôle.
*
Cochez la case « Redémarrer automatiquement le serveur de destination, si nécessaire » et cliquez sur « Installer »:
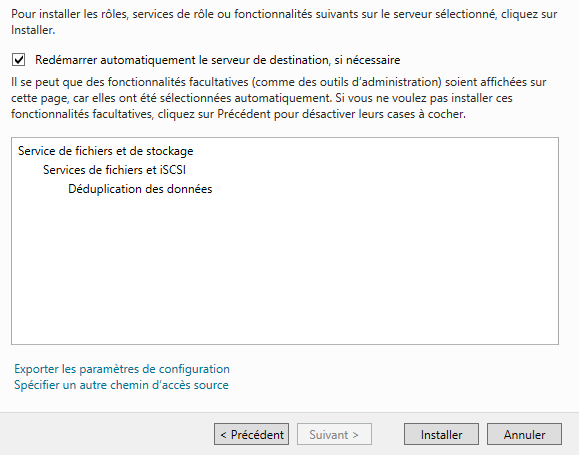
Patientez quelques minutes le temps de l’installation. Une fois finie, cliquez sur « Fermer ». Le rôle de déduplication des données est maintenant installé.
*
Analyse et activation
Lors de l’installation du rôle un outil qui va nous être très utile à été installé. Il s’agit de « ddpeval ». Cet outil va nous permettre d’évaluer les économies pouvant être réalisées grâce à la déduplication des données avant d’activer celle-ci sur notre disque. Sachez qu’il ne sera pas possible d’activer la déduplication sur la partition qui contient le système. Voici mon infrastructure:

*
Pour lancer l’outil, ouvrez une invite de commande (CMD) et tapez la commande:
ddpeval <votre disque local ou distant>
*
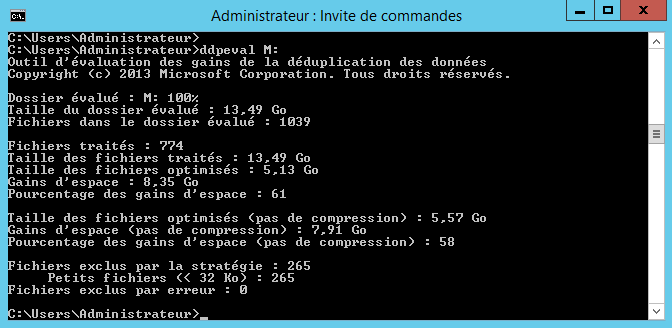
Dans mon cas je vais évaluer M:. L’évaluation prend un peu de temps et dépend de la taille de l’espace à analyser.
*
D’après l’outil, grâce à la déduplication je peux gagner 58% sur mon volume. Maintenant que nous avons analysé l’espace pouvant être gagné, nous allons activer la déduplication des données sur notre disque. Pour cela rien de plus simple, allez dans le gestionnaire de serveur et sur la gauche cliquez sur « Services de fichiers et de stockage« .
*
Cliquez ensuite sur « Disques« .
*
Pour commencer, sélectionnez votre disque dans la liste, puis un peu plus en bas dans « Volumes » faites un clic droit sur votre volume et sélectionnez « Configurez la déduplication des données…«

*
Vous arriverez sur les paramètres de la déduplication de votre disque.

*
Dans « Déduplication des données » sélectionnez « Serveur de fichiers à usage général » pour les fichiers de données à usage général ou « Serveur VDI (Virtual Desktop Infrastructure) » lors de la configuration du stockage pour les ordinateurs virtuels en cours d’exécution. Vous pouvez définir au bout de combien de jour doivent être dupliqués les fichiers. Vous pouvez exclure des dossiers de la déduplication. Enfin dans « Définir la planification de la déduplication » vous pouvez définir quel jour/heure la déduplication peut être effectuée pour optimiser le débit de votre réseau. Une fois votre configuration faite, cliquez sur OK. La déduplication des données est maintenant configurée. Si vous êtes impatient, vous pouvez lancer le job de déduplication manuellement à l’aide de PowerShell. Ouvrez PowerShell en tant qu’administrateur et entrez la commande suivante:
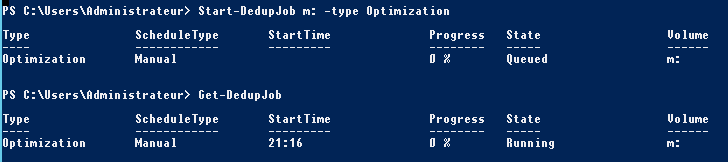
Start-DedupJob <votre disque local ou distant> -type Optimization
*
Pour suivre l’avancement entrez la commande:
Get-DedupJob
*
*
Résultat
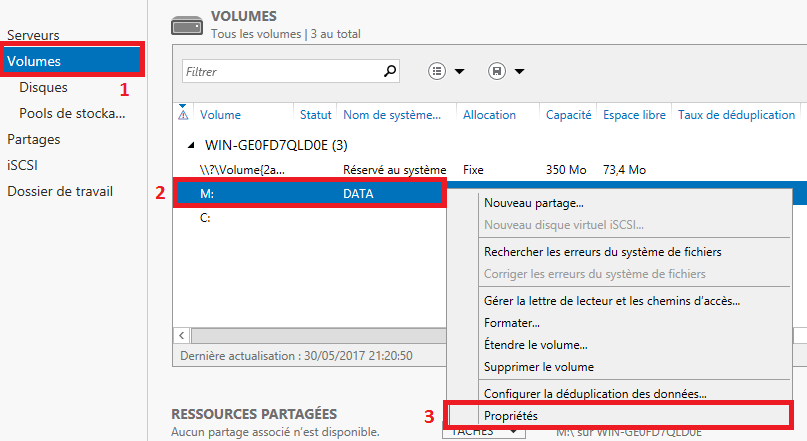
Pour visualiser le résultat, toujours dans le rôle « Services de fichiers et de stockage ». Cliquez sur « Volume » , sélectionnez votre volume, faites un clic droit et sélectionner « Propriétés ».
*
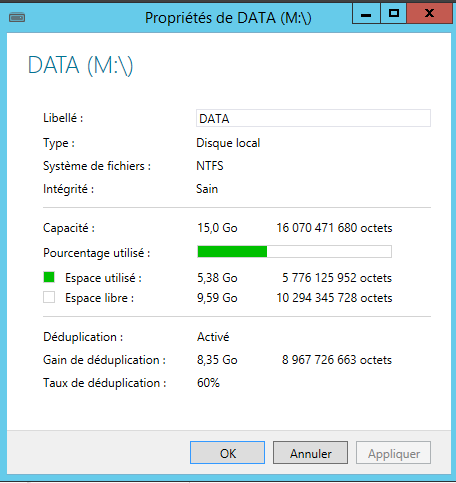
Vous arriverez sur la page ci-dessous, dans mon cas la déduplication des données m’a permis de gagner 60% d’espace de stockage!
*
Vous savez désormais ce qu’est la déduplication des données mais aussi comment mettre en place celle-ci sur Windows Server. Si vous souhaitez optimiser d’avantage votre infrastructure au niveau stockage n’hésitez pas à consulter mon article sur la technologie RAID.
Ping : Déduplication des données – TOOLS BOX CPTG